查找的学问
当我们翻开新华字典,我们都会知道如果要查一个字的话,我们一般都会取目录里面查看,找到对应的字。 但是机器怎么找东西?
于是出现了各种查找算法
- 顺序查找:傻瓜遍历
- 二分查找:递归的进行1/2的查找,直到逼近数值,需要数据有序
- 插值查找:基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。需要数据有序
- 斐波那契查找:是二分查找的一种提升算法,通过运用黄金比例的概念在数列中选择查找点进行查找,提高查找效率。需要数据有序
- 树表查找:二叉查找树,B/B+树,红黑树这些进行查找的数据结构(B/B+树,红黑树是通过2-3树改进而来的)需要数据有序
- 分块查找
- hash查找
我们可以知道了,查找比较快速的方式都是通过辅助的数据结构进行查找的。
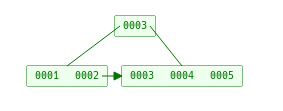
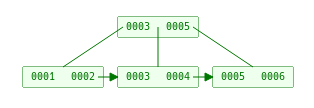
B+tree定义
首先b+tree有一个Max. Degree(我们称这个为阶)的定义
对于一个m阶的B+树有下面的限制条件
-
树中每个结点最多含有m个孩子(m>=2)
-
除根结点和叶子结点外,其它每个结点至少有[ceil(m / 2)]个孩子(其中ceil(x)是一个取上限的函数)
-
若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点)
-
所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null)
联合索引
mysql的索引是使用的B+树。 如果定义一个联合索引包含 地区id,姓,国家(area_id,name,country),mysql在构建b+tree的时候会按照id首先进行插入位置的确定。如果area_id都是一致的话,这样就继续比价后面两个字段。
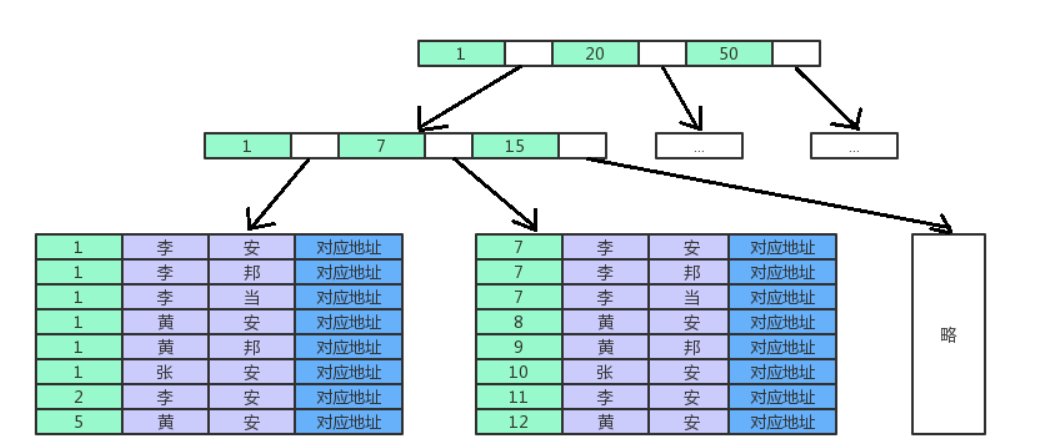
最左匹配原则
如上面的 area_id,name,country 联合索引,如果我们查询
// 无法命中联合索引
select * from table where name='张' and country='安'
// 可以命中联合索引
select * from table where area_id=1 and country='安'
上面的情况是因为,area_id是mysql进行索引遍历的第一个先要条件,如果没有这个条件。 那么就无法使用索引了。
如果第一个匹配了才接着下一个列的匹配
这就是为什么会有最左匹配原则
二级索引
一个表中的所有索引除了聚集索引,其他的都是二级索引
辅助索引,其叶子节点并不包含行记录的全部数据,叶子结点除了包含键值以外,每个叶子结点中的索引行还包含了一个书签,该书签用来告诉存储引擎可以在哪找到相应的数据行,由于innodb引擎表是索引组织表,因此innodb存储引擎的辅助索引的书签就是相应行数据的聚集索引键
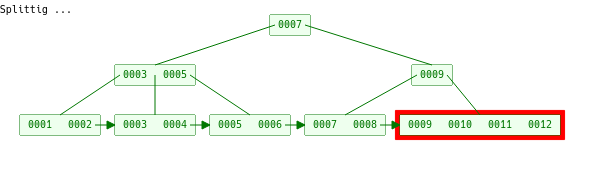
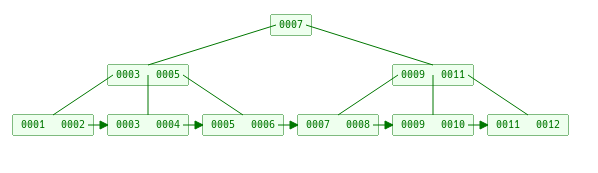
b树的分裂
按照定义如果节点的长度超过了阶的大小就要进行分裂