磁盘
我们知道传统的硬盘是通过旋转盘片和抖动磁头来实现数据的读取。 操作系统会通过硬盘的驱动取发生读取指令,硬盘做出相应的回应。 操作系统有多种算法来进行硬盘的调度:
- 先来先服务
- 最短寻找时间优先
- 扫描(SCAN)算法(又称电梯算法)
- 循环扫描(Circulair SCAN, C-SCAN)算法
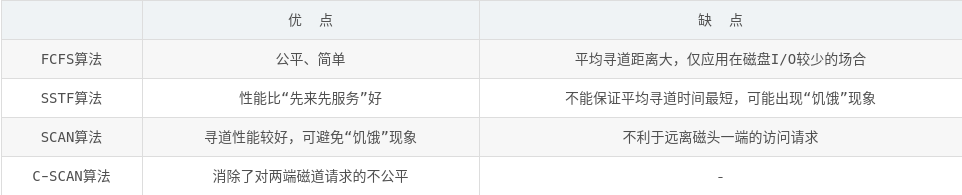

磁盘模型是这样的
图中指向的那个环就是一个磁盘块,磁盘是典型的块设备,所以这些条也就是硬盘分区被划分为一个个的block,每个块的大小被定为1024、2048或4096字节。
这些分区具体被分为多大其实这些分块是被一个叫boot block的东西管理着:
boot block:boot block 是芯片设计厂家在LPC2000系列微控制器内部固化的一段代码,用户无法对其修改和删除。这段代码在芯片复位后首先被运行,其功能主要是判断运行那个存储器上的程序、检查用户代码是否有效、判断芯片是否被加密、芯片的在应用以及在系统编程功能。
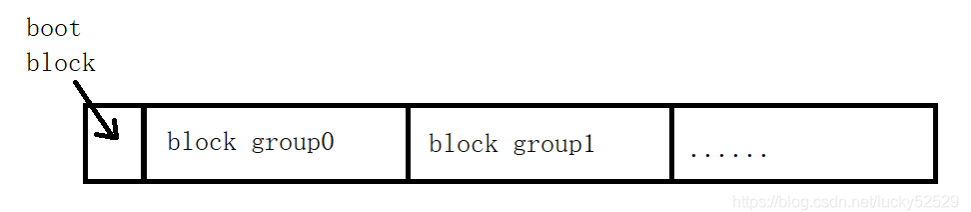
其实我们的文件就存储在block group上,并且对于磁盘是连续的
block group结构:
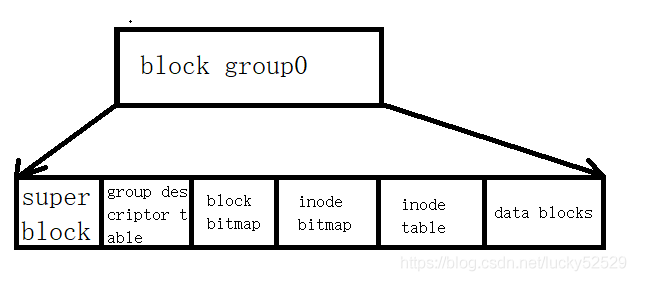
各个部分解析
inode table: inode是一个结构体,inode结构体中存放的就是文件的属性
inode bitmap:我们每个文件都对应了一个inode,每个inode拥有独一无二inode号。
block bitmap:Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没 有被占用
data blocks:存放数据的数据块
super block:存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量, 未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的 时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个 文件系统结构就被破坏了
group descriptor table:块组描述符,描述块组属性信息
数据存放
一个文件的数据是如何存放到磁盘中的:
- 检查inode位图是否为空
- 如果某比特位为空则将其由0置为1
- 把对应的文件属性写在此inode位图相应的inode节点中
- 给这个对应的inode号分配block空间,写入数据
- 将这个block块号也存到inode中,并把对应的block bitmap所对应的位置置为1
- 将文件名字和ionde号映射关系写入目录文件的内容中
再来看看如何删除磁盘中的一个文件:
- 将文件对应的数据block块从1置为0
- 将文件对应的inode号从1置为0
mysql的文件表结构
假设你已经装好了MySQL最新的5.7版本(译注:文章发布于17年4月),并且你创建了一个windmills库(schema)和wmills表。在文件目录(通常是/var/lib/mysql/)你会看到以下内容:
data/
windmills/
wmills.ibd
wmills.frm
这是因为从MySQL 5.6版本开始innodb_file_per_table参数默认设置为1。该配置下你的每一个表都会单独作为一个文件存储(如果有分区也可能有多个文件)。
目录下要注意的是这个叫wmills.ibd的文件。这个文件由多个段(segments)组成,每个段和一个索引相关。
文件的结构是不会随着数据行的删除而变化的,但段则会跟着构成它的更小一级单位——区的变化而变化。区仅存在于段内,并且每个区都是固定的1MB大小(页体积默认的情况下)。页则是区的下一级构成单位,默认体积为16KB。
按这样算,一个区可以容纳最多64个页,一个页可以容纳2-N个行。行的数量取决于它的大小,由你的表结构定义。InnoDB要求页至少要有两个行,因此可以算出行的大小最多为8000 bytes。
段 -> 区 -> 页
听起来就像俄罗斯娃娃(Matryoshka dolls)一样是么,没错!下面这张图能帮助你理解:
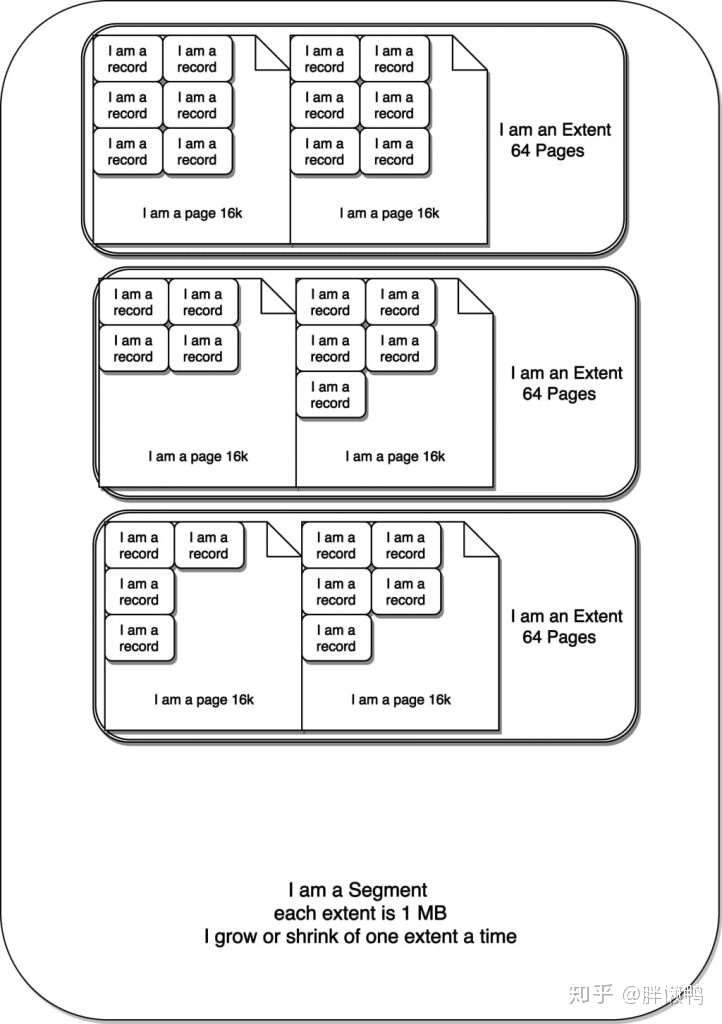
主键索引和页
主键索引的结构是和硬盘的文件分布是连续的
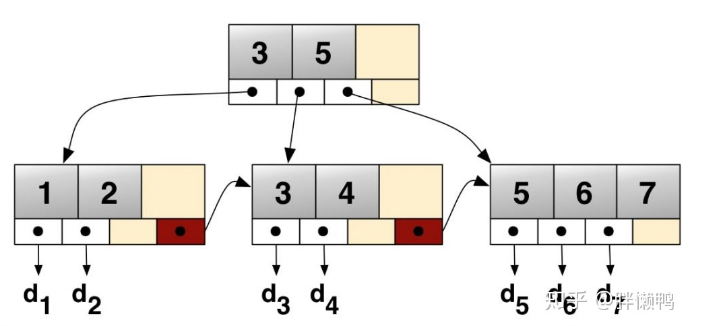
主键的文件描述
ROOT NODE #3: 4 records, 68 bytes
NODE POINTER RECORD ≥ (id=2) → #197
INTERNAL NODE #197: 464 records, 7888 bytes
NODE POINTER RECORD ≥ (id=2) → #5
LEAF NODE #5: 57 records, 7524 bytes
RECORD: (id=2) → (uuid="884e471c-0e82-11e7-8bf6-08002734ed50", millid=139, kwatts_s=1956, date="2017-05-01", location="For beauty's pattern to succeeding men.Yet do thy", active=1, time="2017-03-21 22:05:45", strrecordtype="Wit")
CREATE TABLE `wmills` (
`id` bigint(11) NOT NULL AUTO_INCREMENT,
`uuid` char(36) COLLATE utf8_bin NOT NULL,
`millid` smallint(6) NOT NULL,
`kwatts_s` int(11) NOT NULL,
`date` date NOT NULL,
`location` varchar(50) COLLATE utf8_bin DEFAULT NULL,
`active` tinyint(2) NOT NULL DEFAULT '1',
`time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`strrecordtype` char(3) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`id`),
KEY `IDX_millid` (`millid`)
) ENGINE=InnoDB;
所有的B树都有着一个入口,也就是根节点,在上图中#3就是根节点。根节点(页)包含了如索引ID、INodes数量等信息。INode页包含了关于页本身的信息、值的范围等。最后还有叶子节点,也就是我们数据实际所在的位置。在示例中,我们可以看到叶子节点#5有57行记录,共7524 bytes。在这行信息后是具体的记录,可以看到数据行内容。
这里想引出的概念是当你使用InnoDB管理表和行,InnoDB会将他们会以分支、页和记录的形式组织起来。
页是InnoDB管理存储空间的基本单位,一个页的大小默认是16KB。
InnoDB不是按行的来操作的,它可操作的最小粒度是页,页加载进内存后才会通过扫描页来获取行/记录。
页的内部原理


页可以空或者填充满(100%),行记录会按照主键顺序来排列。例如在使用AUTO_INCREMENT时,你会有顺序的ID 1、2、3、4等。
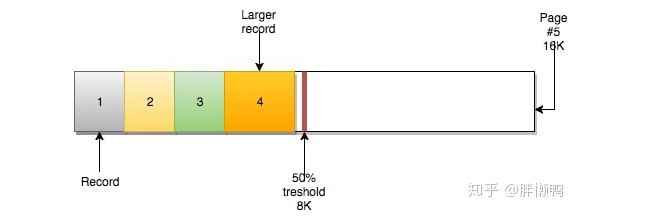
页还有另一个重要的属性:MERGE_THRESHOLD。该参数的默认值是50%页的大小,它在InnoDB的合并操作中扮演了很重要的角色。
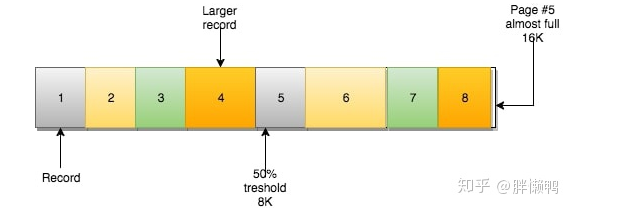
当你插入数据时,如果数据(大小)能够放的进页中的话,那他们是按顺序将页填满的。
若当前页满,则下一行记录会被插入下一页(NEXT)中。
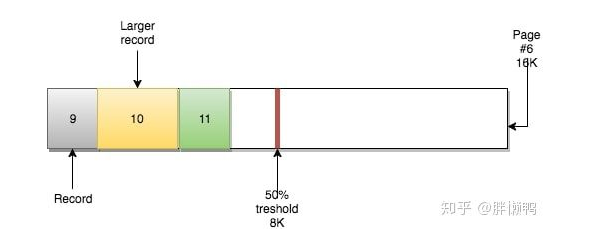
根据B树的特性,它可以自顶向下遍历,但也可以在各叶子节点水平遍历。因为每个叶子节点都有着一个指向包含下一条(顺序)记录的页的指针。
例如,页#5有指向页#6的指针,页#6有指向前一页(#5)的指针和后一页(#7)的指针。
这种机制下可以做到快速的顺序扫描(如范围扫描)。之前提到过,这就是当你基于自增主键进行插入的情况。
但如果你不仅插入还进行删除呢?这就要看看页的合并了
页的分类(Innodb)
- 数据页(b-tree)本文针对的页类型
- undo页面 (事务undo log)
- 系统页 (system page)
- 事务数据页 (transaction system page)
- 插入缓冲位图页 (insert buffer bitmap)
- 插入缓冲空闲列表页
- 未压缩的二进制大对象页
- 压缩的二进制大对象页
页合并
当你删了一行记录时,实际上记录并没有被物理删除,记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。
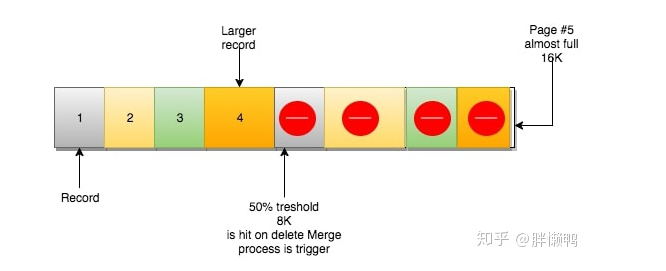
当页中删除的记录达到MERGE_THRESHOLD(默认页体积的50%),InnoDB会开始寻找最靠近的页(前或后)看看是否可以将两个页合并以优化空间使用。
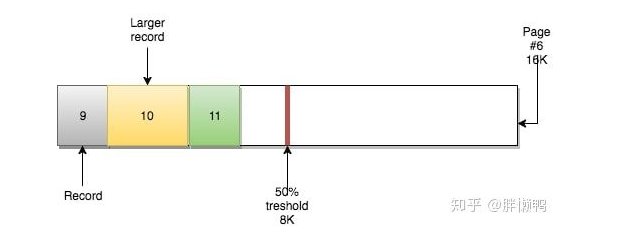
当前后两个页面可以合并成一个页面的时候,我们就可以将他们合并在一起
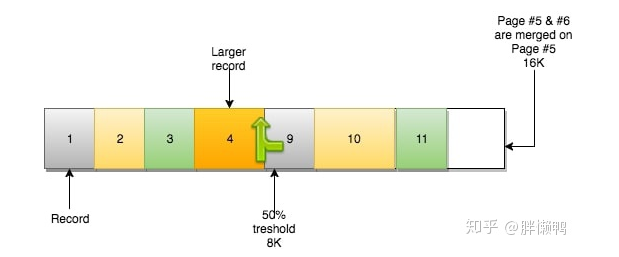
合并操作使得页#5保留它之前的数据,并且容纳来自页#6的数据。页#6变成一个空页,可以接纳新数据
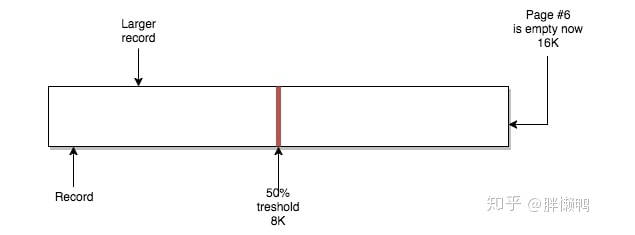
如果我们在UPDATE操作中让页中数据体积达到类似的阈值点,InnoDB也会进行一样的操作。
页分裂
页可能填充至100%,在页填满了之后,下一页会继续接管新的记录。
但是如果遇到本页无法容纳行记录,但是下一页页无法容纳的话就需要进行页分裂
#10 无法容纳
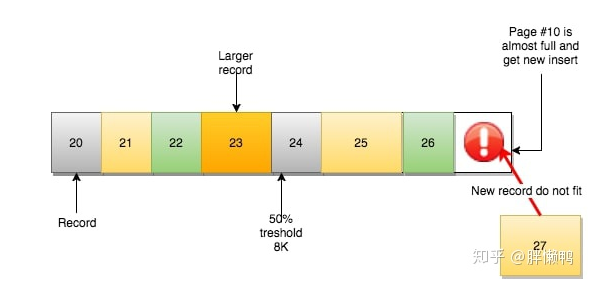
#11 页无法容纳
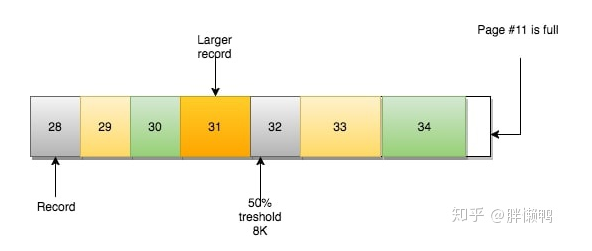
还记得之前说的链表吗(译注:指B+树的每一层都是双向链表)?页#10有指向页#9和页#11的指针。
InnoDB的做法是(简化版):
- 创建新页
- 判断当前页(页#10)可以从哪里进行分裂(记录行层面)
- 移动记录行
- 重新定义页之间的关系
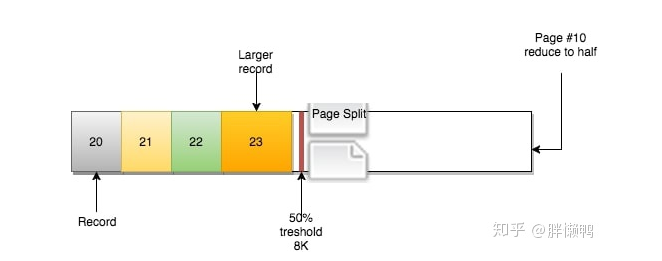
新的页#12被创建:
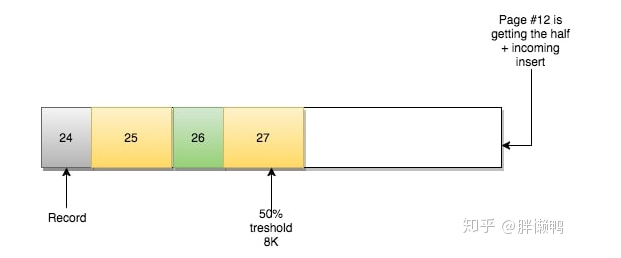
页#11保持原样,只有页之间的关系发生了改变:
- 页#10相邻的前一页为页#9,后一页为页#12
- 页#12相邻的前一页为页#10,后一页为页#11
- 页#11相邻的前一页为页#10,后一页为页#13
页分裂会发生在插入或更新,并且造成页的错位(dislocation,落入不同的区),导致主键性能降低
InnoDB用INFORMATION_SCHEMA.INNODB_METRICS表来跟踪页的分裂数。可以查看其中的index_page_splits和index_page_reorg_attempts/successful统计。
行格式
主键设计
好的主键不仅对于数据查找很重要,而且也影响写操作时数据在区上的分布(也就是与页分裂和页合并操作相关)。
下面分别有三个测试:
- 自增主键
- 1-200的ID与自增值作为主键
- 1-200的ID与UUID联合作为主键
测试分裂的次数如下图 从左到右分别为 测试1,测试2,测试3
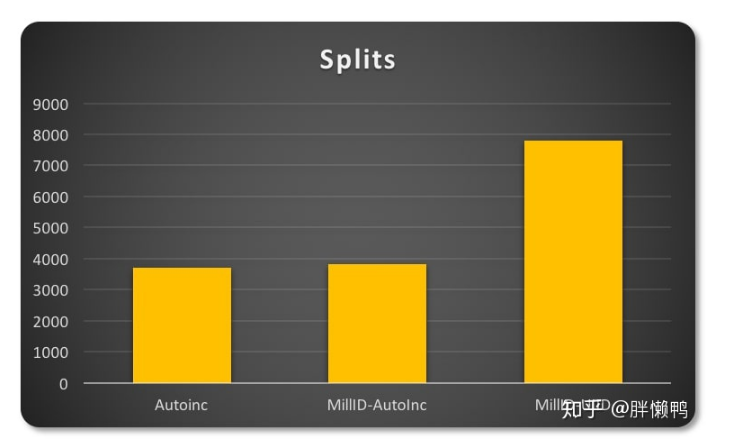
表现因不同主键而异。
在头两种情况中数据的分布更为紧凑,也就是说他们拥有更好的空间利用率。对比半随机(semi-random)特性的UUID会导致明显的页稀疏分布(页数量更多,相关分裂操作更多)。
在页合并的情况中,尝试合并的次数因主键类型的不同而表现得更加不一致。
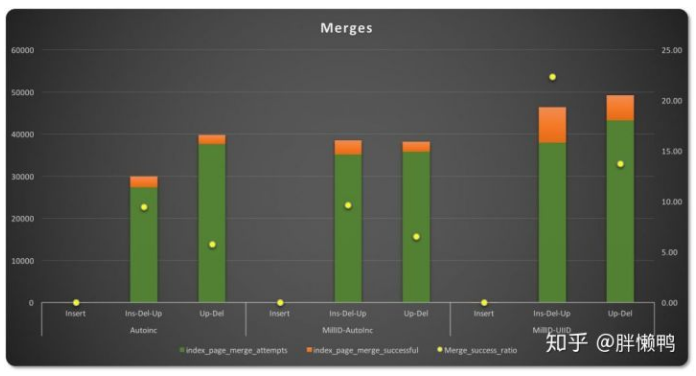
在插入-更新-删除操作中,自增主键有更少的合并尝试次数,成功比例比其他两种类型低9.45%。UUID型主键(图表的右一侧)有更多的合并尝试,但是合并成功率明显更高,达22.34%,因为数据稀疏分布让很多页都有部分空闲空间。
在辅助索引与上面主键索引相似的情况下,测试的表现也是类似的。
行结构
格式有几种 Compact、Redundant、Dynamic和Compressed
Compact行格式

变长字段长度列表:VARCHAR(M)、VARBINARY(M)、TEXT类型,BLOB类型,这些数据类型修饰列称为变长字段,变长字段中存储多少字节的数据不是固定的,所以我们在存储真实数据的时候需要顺便把这些数据占用的字节数也存起来。
CHAR是一种固定长度的类型,VARCHAR则是一种可变长度的类型。
VARCHAR(M),M代表最大能存多少个字符。( MySQL5.0.3以前是字节,以后就是字符)
NULL值列表(标志位):Compact行格式会把可以为NULL的列统一管理起来,存一个标记为在NULL值列表中,如果表中没有允许存储NULL 的列,则 NULL值列表也不存在了。
- 二进制位的值为1时,代表该列的值为NULL
- 二进制位的值为0时,代表该列的值不为NULL
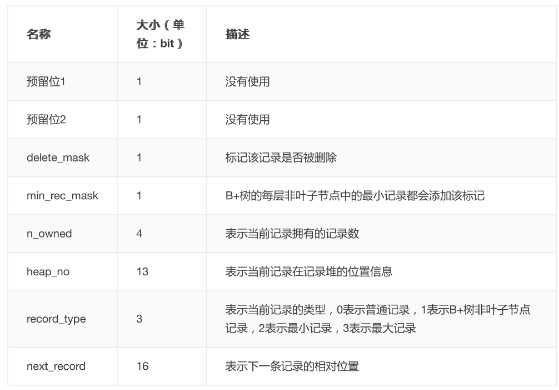
记录头信息:除了变长字段长度列表、NULL值列表之外,还有一个用于描述记录的记录头信息,它是由固定的5个字节组成
5个字节也就是40个二进制位,不同的位代表不同的意思,如图:
真实数据: 记录的真实数据除了我们自己定义的列的数据以外,还会有三个隐藏列
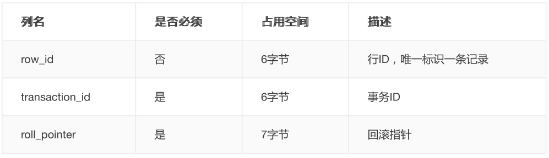
实际上这几个列的真正名称其实是:DB_ROW_ID、DB_TRX_ID、DB_ROLL_PTR。
一个表没有手动定义主键,则会选取一个Unique键作为主键,如果连Unique键都没有定义的话,则会为表默认添加一个名为row_id的隐藏列作为主键。所以row_id是在没有自定义主键以及Unique键的情况下才会存在的。
行溢出数据:VARCHAR(M)类型的列最多可以占用65535个字节。其中的M代表该类型最多存储的字符数量,如果我们使用ascii字符集的话,一个字符就代表一个字节,我们看看VARCHAR(65535)是否可用:
mysql> CREATE TABLE varchar_size_demo(
-> c VARCHAR(65535)
-> ) CHARSET=ascii ROW_FORMAT=Compact;
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type,not counting BLOBs, is 65535. This includes storage overhead, check the manual. You
have to change some columns to TEXT or BLOBs
mysql>
报错信息表达的意思是:MySQL对一条记录占用的最大存储空间是有限制的,除BLOB或者TEXT类型的列之外,其他所有的列(不包括隐藏列和记录头信息)占用的字节长度加起来不能超过65535个字节。这个65535个字节除了列本身的数据之外,还包括一些其他的数据,比如说我们为了存储一个VARCHAR(M)类型的列,其实需要占用3部分存储空间:
- 真实数据
- 变长字段真实数据的长度
- NULL值标识
一个页的大小一般是16KB,也就是16384字节,而一个VARCHAR(M)类型的列就最多可以存储65533个字节,这样就可能出现一个页存放不了一条记录。
在Compact和Reduntant行格式中,对于占用存储空间非常大的列,在记录的真实数据处只会存储该列的一部分数据,把剩余的数据分散存储在几个其他的页中,然后记录的真实数据处用20个字节存储指向这些页的地址(当然这20个字节中还包括这些分散在其他页面中的数据的占用的字节数),从而可以找到剩余数据所在的页。
Dynamic和Compressed行格式
这两种行格式类似于COMPACT行格式,只不过在处理行溢出数据时有点儿分歧,它们不会在记录的真实数据处存储一部分数据,而是把所有的数据都存储到其他页面中,只在记录的真实数据处存储其他页面的地址。另外,Compressed行格式会采用压缩算法对页面进行压缩。