raft协议是什么
Raft 是一个易于理解的一致性算法。它在容错性和性能方面与 Paxos 相当。不同之处在于,它被分解成相对独立的子问题,而且它干净利落地解决了实际系统所需的所有主要部分。我们希望 Raft 将向更广泛的受众提供协商一致意见,并希望这一更广泛的受众将能够开发各种比目前更高质量的基于协商一致意见的系统。
什么是共识(分布式共识)
一致性是容错分布式系统中的一个基本问题。协商一致涉及到多个服务器就价值观达成一致。一旦他们就一个价值做出决定,这个决定就是最终的决定。当大多数服务器可用时,典型的一致性算法能起到作用; 例如,即使有两台服务器出现故障,一个由5台服务器组成的集群也可以继续运行。 但是如果更多的服务器出现故障,它们将停止进度(但永远不会返回错误的结果)。
图解
日志复制
当我们只有一个节点的时候就很容易达到共识

但是如果我们有多个节点? 这就是分布式共识
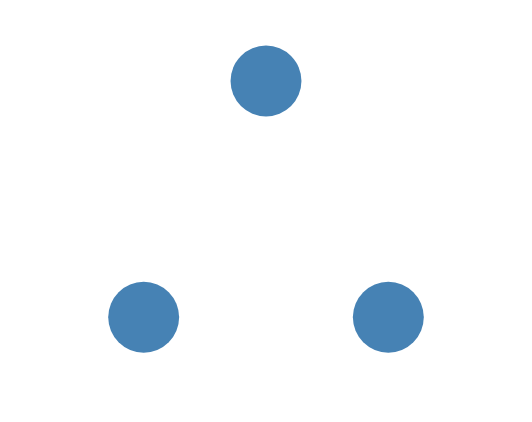
每个节点都有几种状态 随从状态:无边框 候选状态:虚线边框 领导状态:实线边框
一开始大家都是随从状态
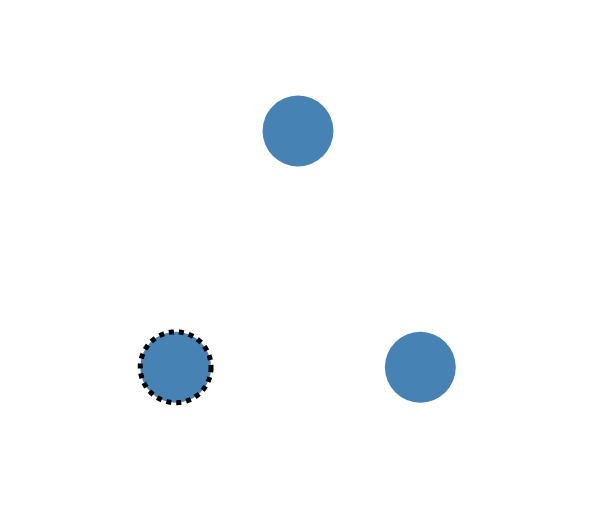
如果没有领导发声明,任何一个随从都可以进行选举
可以请求其他节点投票
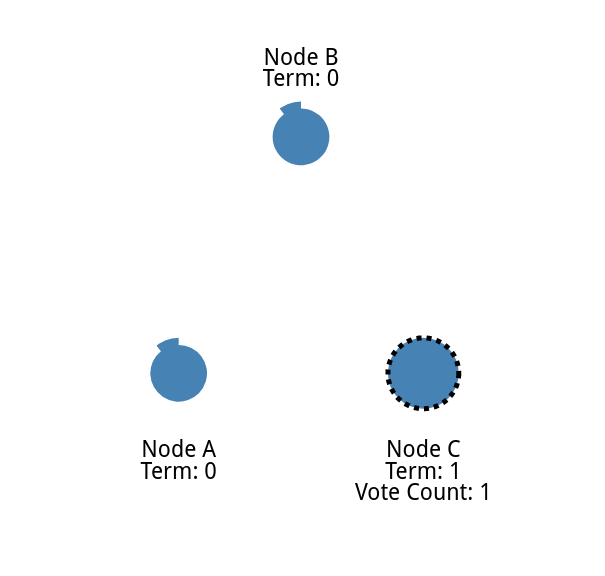
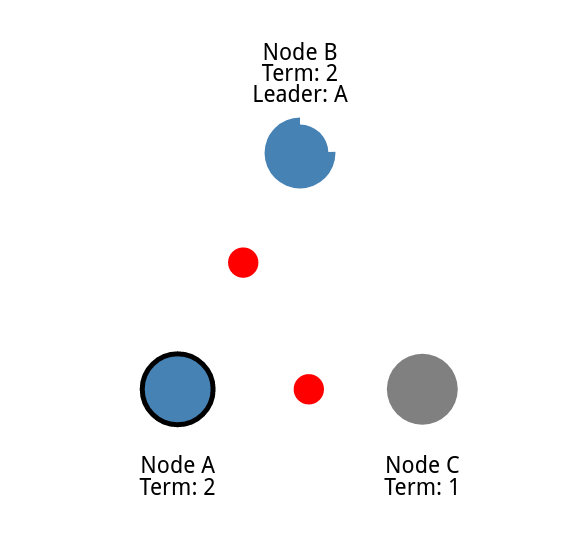
如果候选人获得大多数节点的选票,那么候选人就成为领导者。 这个过程被称为领导人选举。
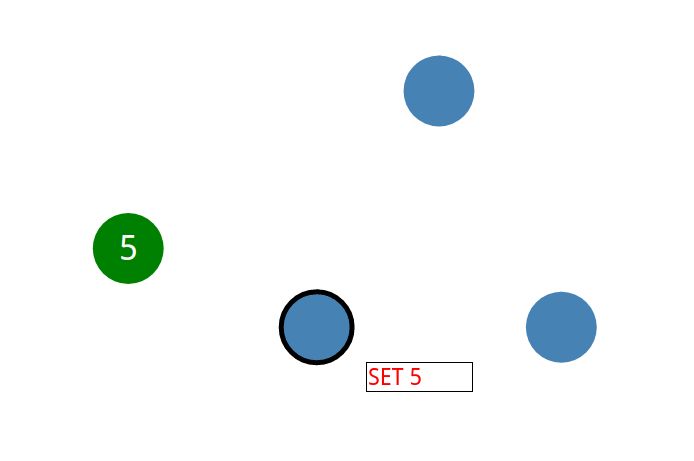
系统的所有改变现在都要经过领导者。
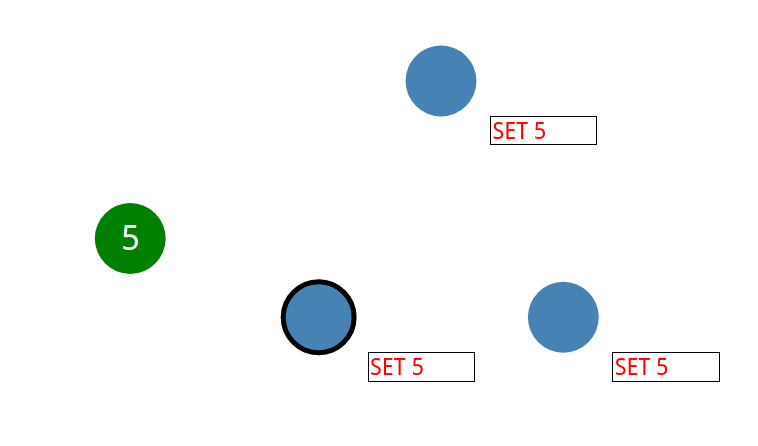
由领导节点通知随从节点,这个时候数据还未真实生效
通知到位后,领导节点就真实写入数据
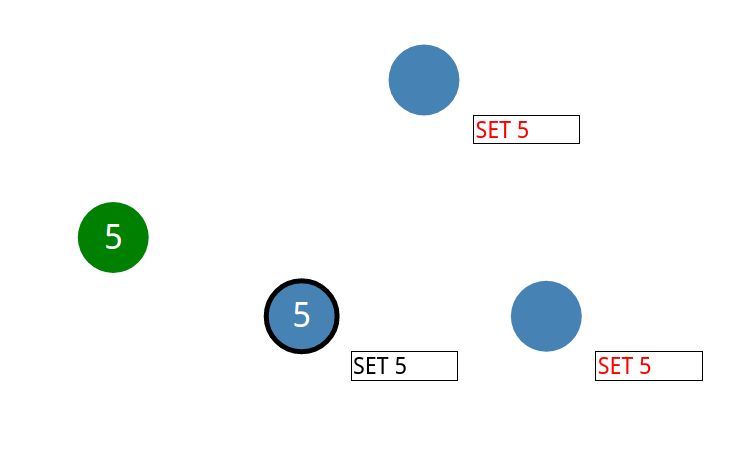
然后领导再次通知所有节点写入数据
集群现在已经就系统状态达成了共识。这个过程称为日志复制。
节点选举
在 Raft 中有两个超时设置来控制选举
首先是选举超时 : 选举超时是指追随者等待成为候选人的时间。默认150ms ~ 300ms.
选举超时后,跟随者成为候选人,开始新的选举任期
首先为自己投票
然后发送给其他节点,请求投票
如果接收节点在这个任期内还没有投票,那么它就投票给候选人
接收到的节点也会将选集超时时间重置
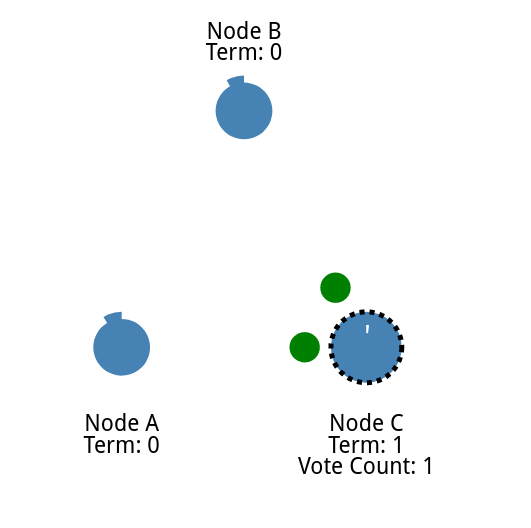
一旦候选人获得多数选票,他就成为领袖
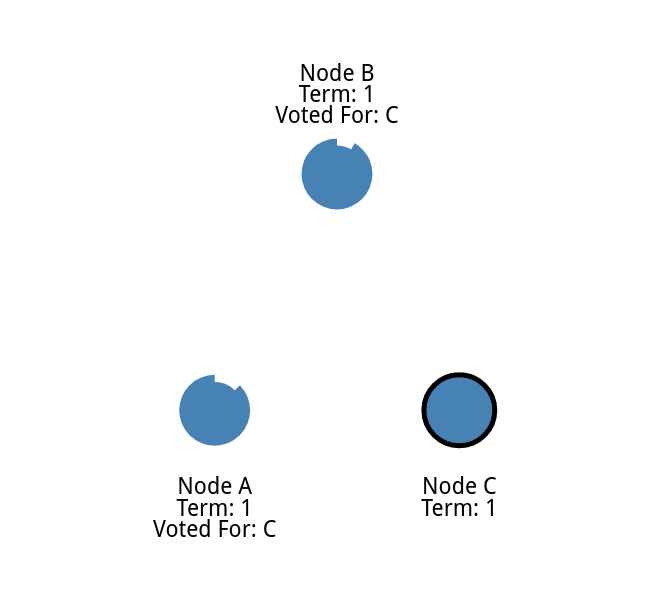
然后领导人就会发送消息通知其他节点作为他的随从 [ step A ]
这些消息以心跳超时指定的间隔发送。
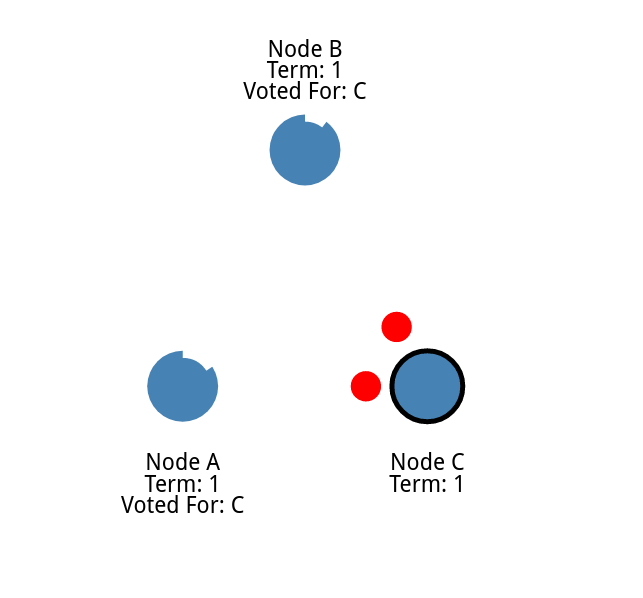
然后跟随者响应 [ step B ]
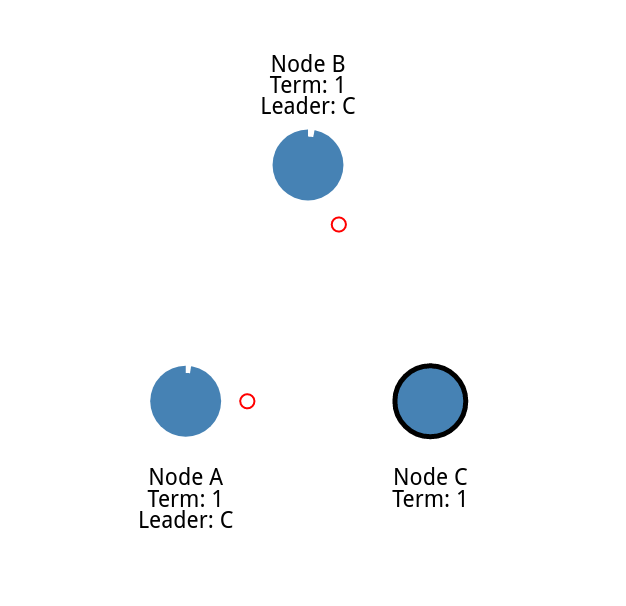
然后就一直重复 step A step B
领导人宕机
领导人宕机了
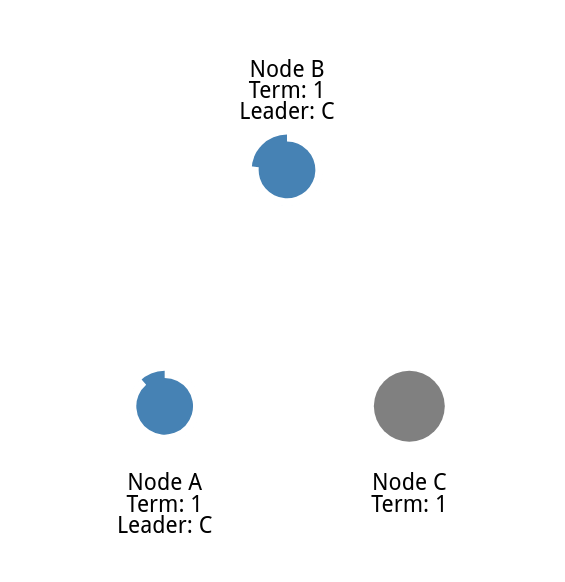
接下来就由选举超时的作为备选人,并且成为领导人
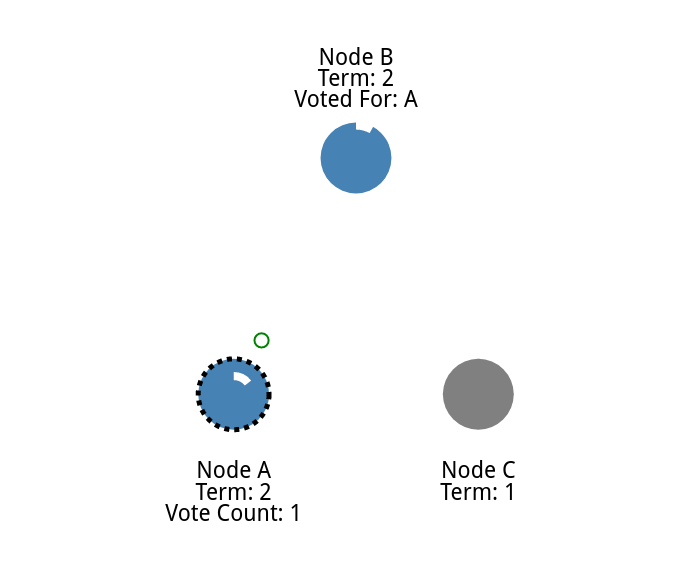
要求多数票保证每届任期只能选出一位领导人
如果两个节点同时成为候选人,就会发生分裂投票。
就可以看一个例子
两个同时进行选举
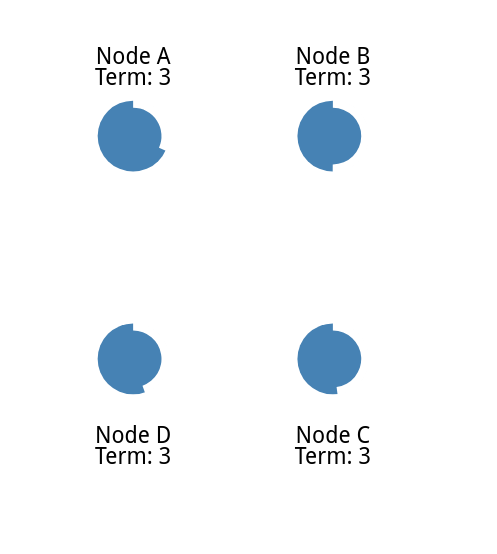
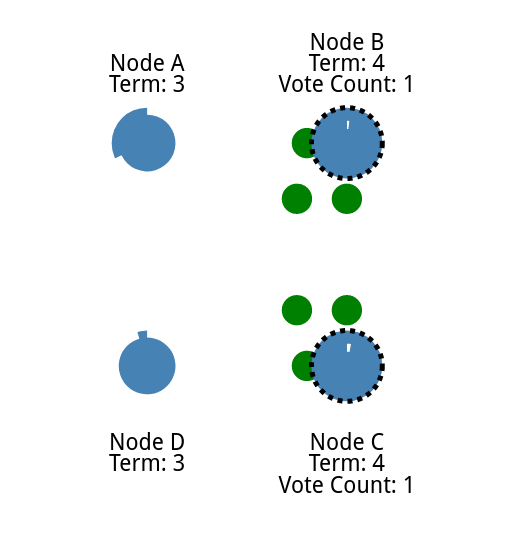
他们同时发送给子节点,每个节点都比另一个节点先到达一个跟随节点。
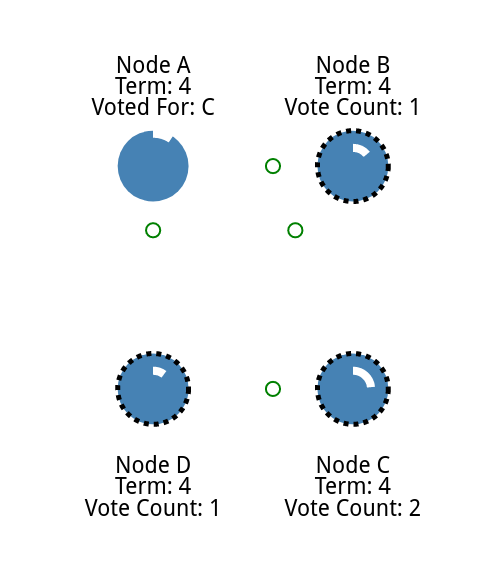
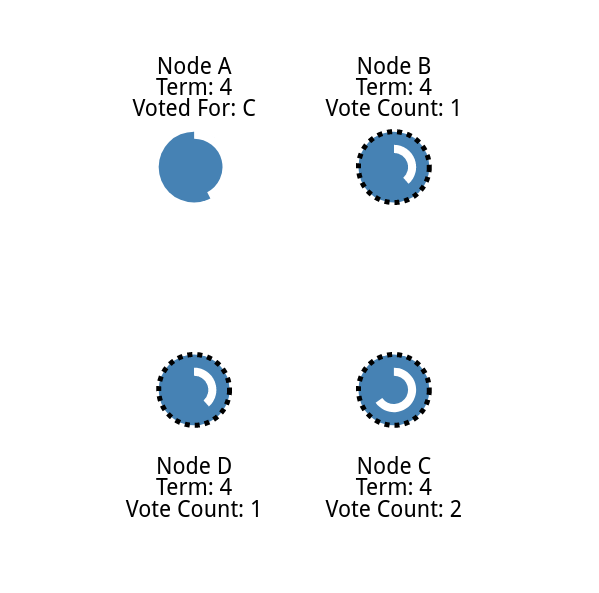
最早得到所有选票的作为领导
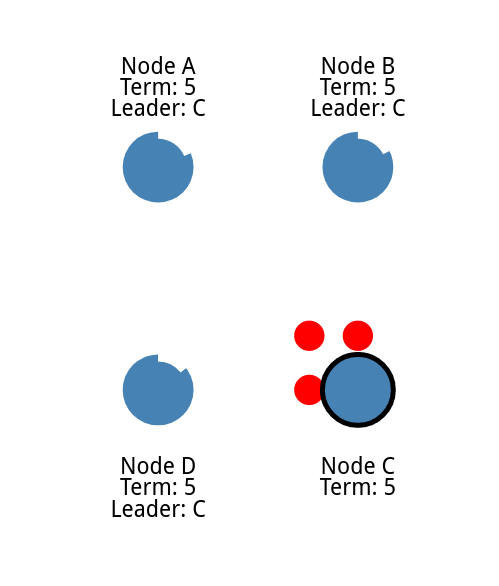
日志同步
一旦我们选出了一个领导者,我们需要将我们系统的所有变化复制到所有节点。
这是通过使用用于心跳的相同的 Append Entries 消息来完成的
下面是过程
领导设置了 5
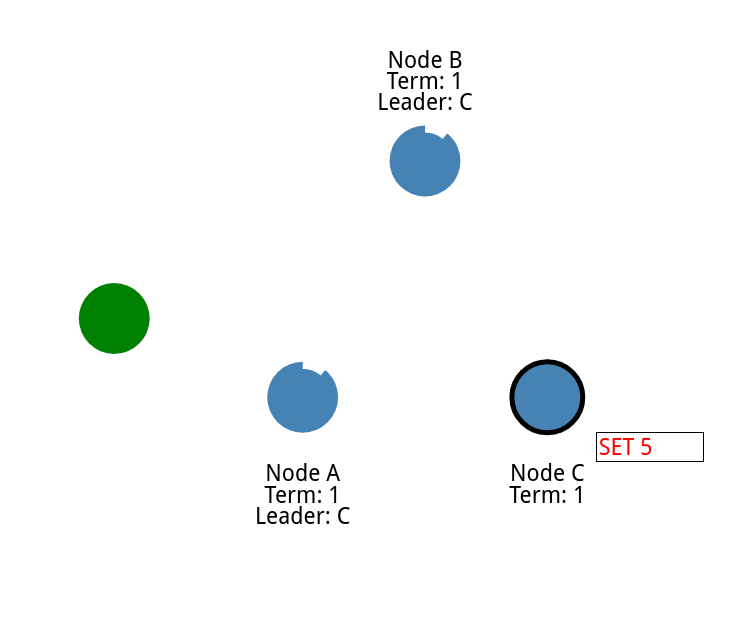
同步给节点
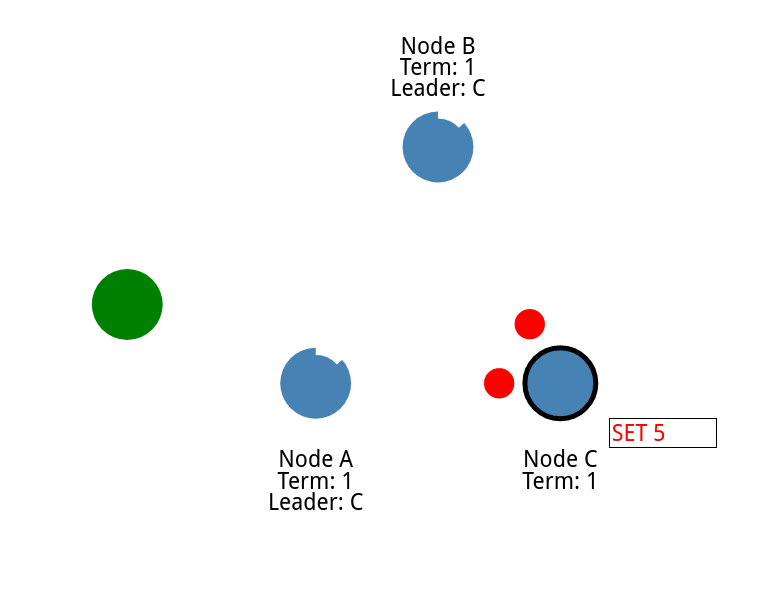
并且发送给client
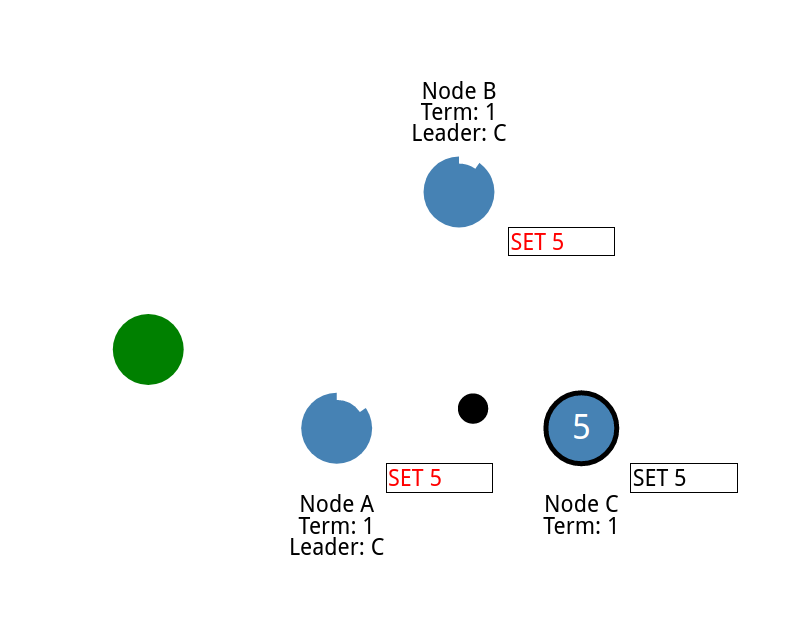
现在发送一个命令让值增加2
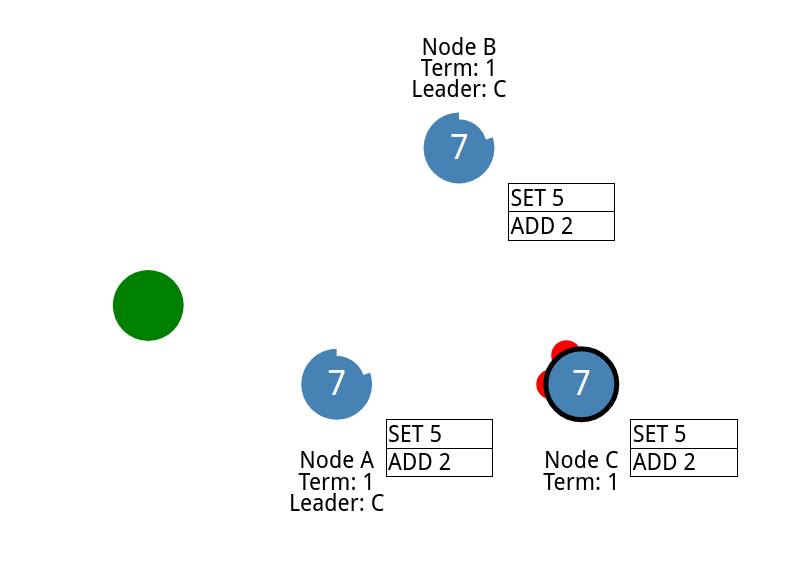
多增加几个节点,并添加分区
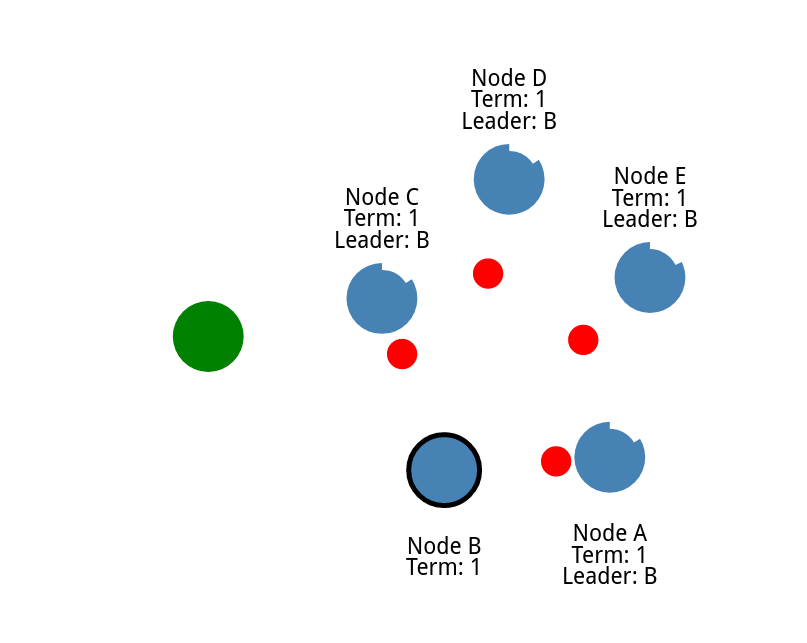
把节点上下分开
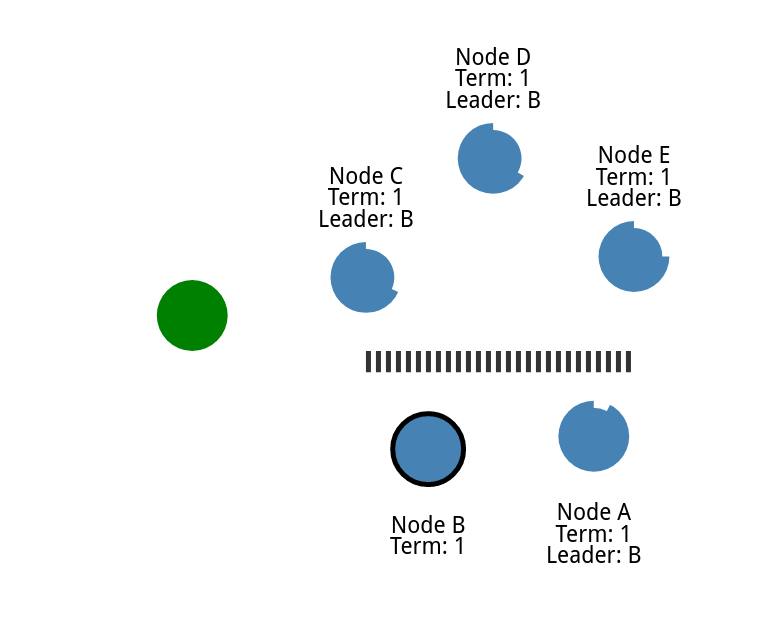
他们就需要各自选举
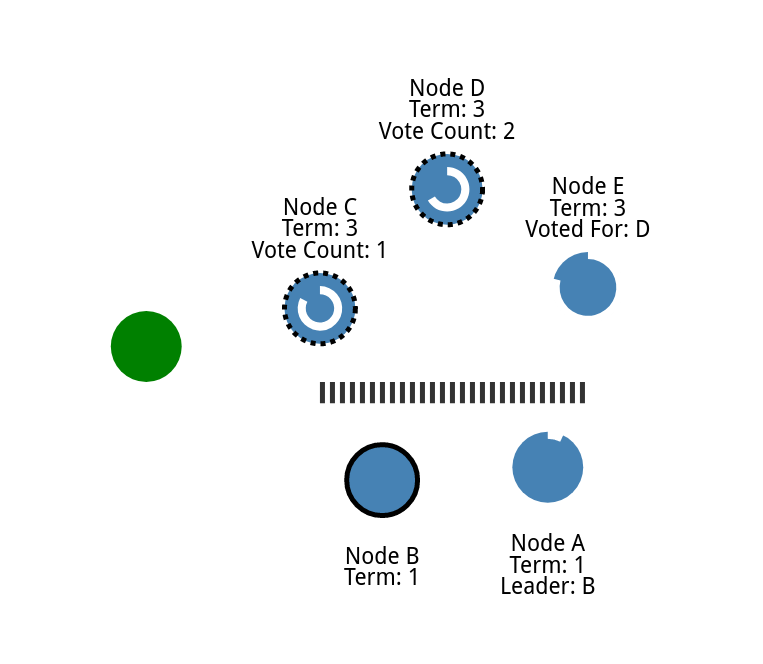
现在我们就有两个不同的集群
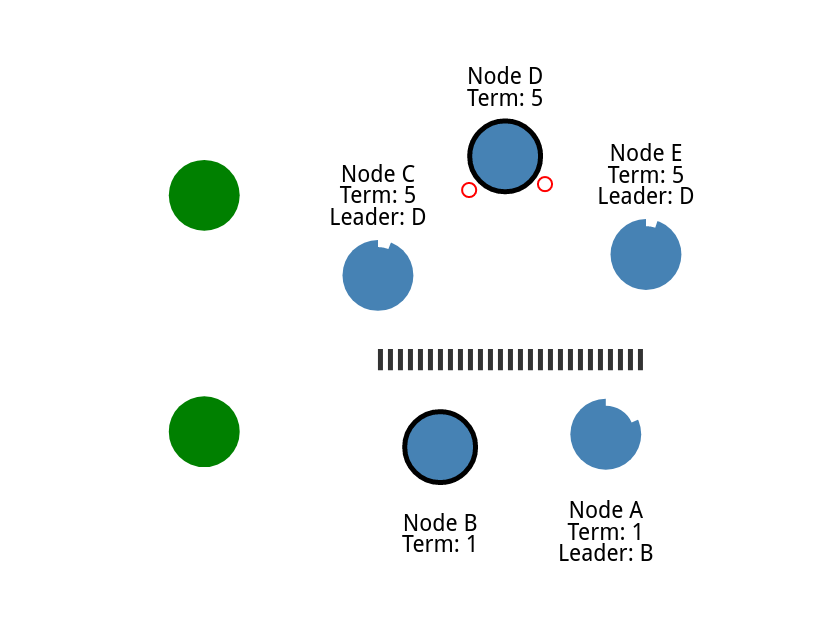
尝试更新两个领导者
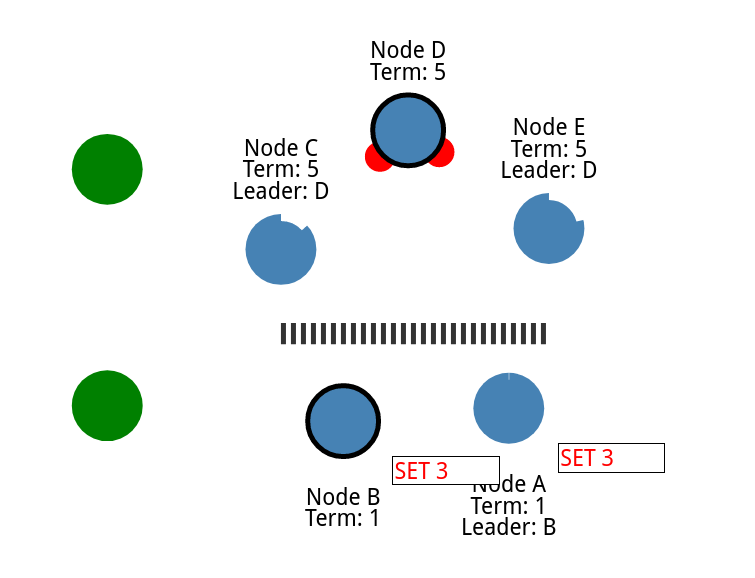
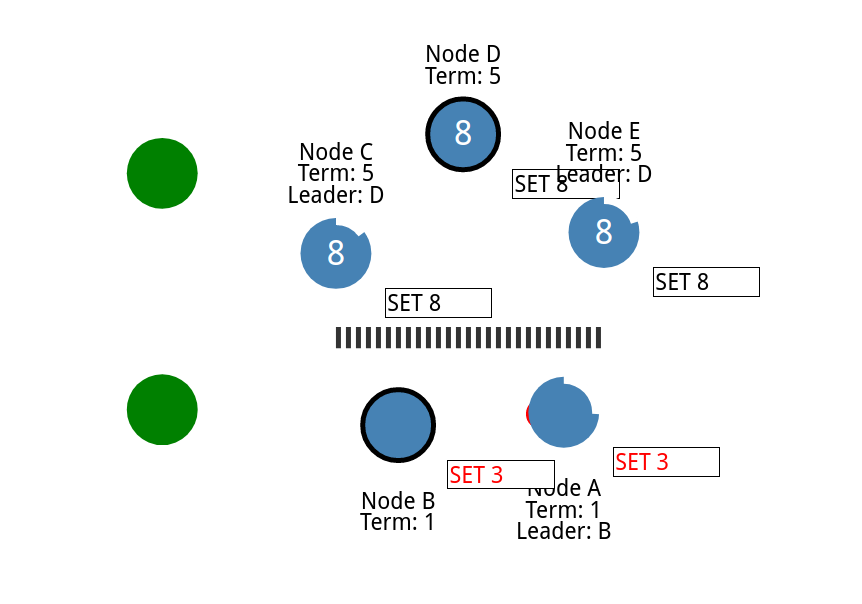
现在我们吧两个间隔取消
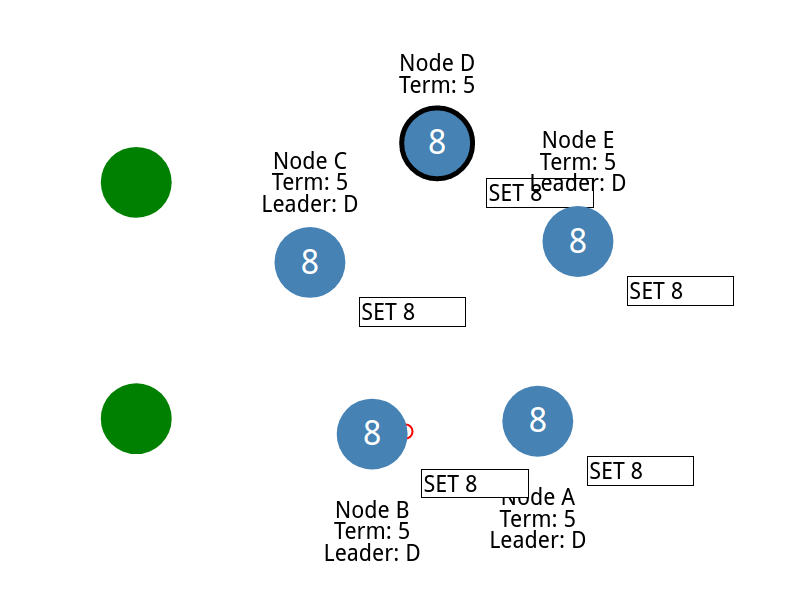
现在我们节点里面的日志就是一致的