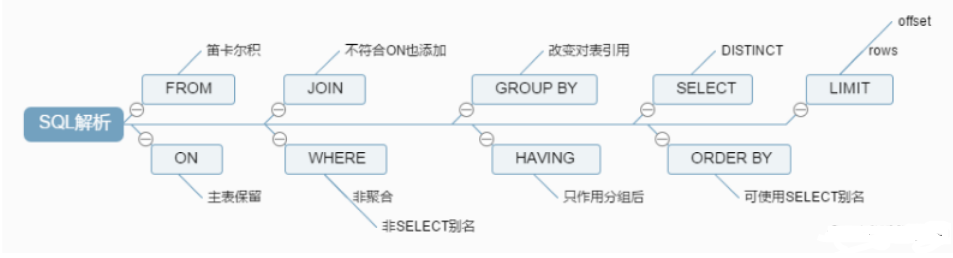
一个普通sql的执行顺序
我们手写sql的顺序:
select <select_list>
from <table_name>
<join_type> join <join_table> on <join_condition>
where <where_condition>
group by <group_by_list>
having <having_condition>
order by <order_by_condition>
limit <limt_number>
实际解析执行的顺序:
from <left table>
on <on_condition>
<join_type> join <join_table>
where <where_condition>
group by <group_by_list>
<sum()avg()等聚合函数>
having <having_condition>
select <select_list>
distinct
order by <order_by_condition>
limit <limit_number>
sql执行的顺序过程其实是:
第一步:加载from子句的前两个表计算笛卡尔积,生成虚拟表vt1;
第二步:筛选关联表符合on表达式的数据,保留主表,生成虚拟表vt2;
第三步:如果使用的是外连接,执行on的时候,会将主表中不符合on条件的数据也加载进来,做为外部行
第四步:如果from子句中的表数量大于2,则重复第一步到第三步,直至所有的表都加载完毕,更新vt3;
第五步:执行where表达式,筛选掉不符合条件的数据生成vt4;
第六步:执行group by子句。group by 子句执行过后,会对子句组合成唯一值并且对每个唯一值只包含一行,生成vt5,。一旦执行group by,后面的所有步骤只能得到vt5中的列(group by的子句包含的列)和聚合函数。
第七步:执行聚合函数,生成vt6;
第八步:执行having表达式,筛选vt6中的数据。having是唯一一个在分组后的条件筛选,生成vt7;
第九步:从vt7中筛选列,生成vt8;
第十步:执行distinct,对vt8去重,生成vt9。其实执行过group by后就没必要再去执行distinct,因为分组后,每组只会有一条数据,并且每条数据都不相同。
第十一步:对vt9进行排序,此处返回的不是一个虚拟表,而是一个游标,记录了数据的排序顺序,此处可以使用别名;
第十二步:执行limit语句,将结果返回给客户端
子查询执行顺序
[子查询执行顺序] 无依赖子查询
比如这种
select * from a where a.b_id in (select id from b where b.id > 100 and b.id < 200)
子查询不依赖外部查询的条件,这种的执行顺序是这样的:
- 先执行子查询,作为where数据传递给外部
- 执行外部查询,并显示整个结果。
[子查询执行顺序] 有依赖子查询
比如这种
select * from a where a.b_id in (select id from b where b.type = a.type) and a.id between 1 and 100
- 从外层查询中取出一个元组,将元组相关列的值传给内层查询。类似:
select type from a.id between 1 and 100=>元组1 - 执行内层查询,得到子查询操作的值。类似
select id from b where type in ([元组1])=>元组2 - 外查询根据子查询返回的结果或结果集得到满足条件的行。
select * from a where a.b_id in () and a.id between 1 and 100 - 然后外层查询取出下一个元组重复做步骤1-3,直到外层的元组全部处理完毕。
on和where的区别
在join的时候on可以筛选被驱动表(left和right join的驱动表不一样)的数据,where只是主表的筛选
表链接的算法
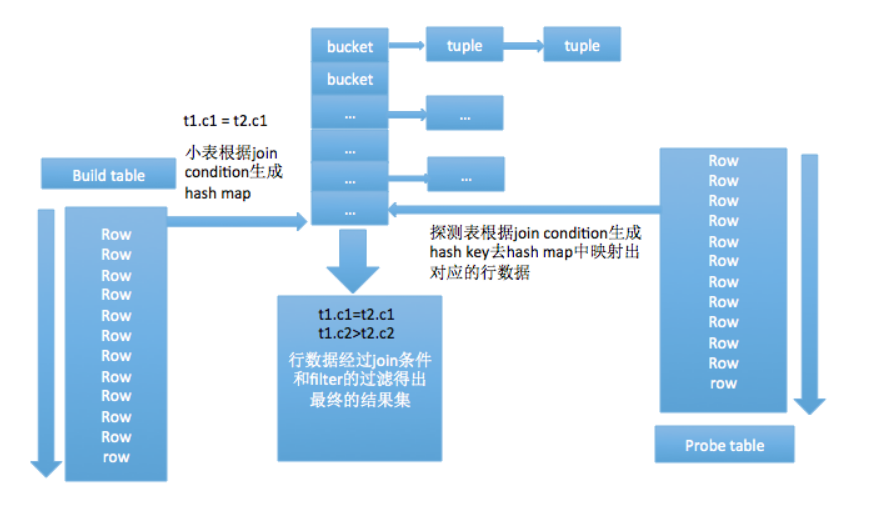
hash-join :
hash join的实现分为build table也就是被用来建立hash map的小表和probe table,首先依次读取小表的数据,对于每一行数据根据连接条件生成一个hash map中的一个元組,数据缓存在内存中,如果内存放不下需要dump到外存。依次扫描探测表拿到每一行数据根据join condition生成hash key映射hash map中对应的元組,元組对应的行和探测表的这一行有着同样的hash key, 这时并不能确定这两行就是满足条件的数据,需要再次过一遍join condition和filter,满足条件的数据集返回需要的投影列。
hash join实现的几个细节:
-
hash join本身的实现不要去判断哪个是小表,优化器生成执行计划时就已经确定了表的连接顺序,以左表为小表建立hash table,那对应的代价模型就会以左表作为小表来得出代价,这样根据代价生成的路径就是符合实现要求的。
-
hash table的大小、需要分配多少个桶这个是需要在一开始就做好的,那分配多少是一个问题,分配太大会造成内存浪费,分配太小会导致桶数过小开链过长性能变差,一旦超过这里的内存限制,会考虑dump到外存,不同数据库有它们自身的实现方式。
-
如何对数据hash,不同数据库有着自己的方式,不同的哈希方法也会对性能造成一定的影响。
nested loop join :
嵌套循环连接.
是比较通用的连接方式,分为内外表,每扫描外表的一行数据都要在内表中查找与之相匹配的行,没有索引的复杂度是O(N*M),这样的复杂度对于大数据集是非常劣势的,一般来讲会通过索引来提升性能。
sort merge-join
merge join需要首先对两个表按照关联的字段进行排序,分别从两个表中取出一行数据进行匹配,如果合适放入结果集;不匹配将较小的那行丢掉继续匹配另一个表的下一行,依次处理直到将两表的数据取完。merge join的很大一部分开销花在排序上,也是同等条件下差于hash join的一个主要原因。